R 是最火熱的分析工具之一
R語言的工程面
Wush Wu
Taiwan R User Group
要有資料,才能分析
需要資料工程
才能不停的取得及時、可分析的資料
關於講者
- Wush Wu
- Taiwan R User Group 創辦人
- 喜歡用R 解決問題
- 快樂的研究人員
- 預測網路廣告的點擊行為
- 快樂的碼農


Taiwan R User Group
MLDMMonday: 每週一分享資料相關議題
主題包含但不限於:
R 套件使用
機器學習和統計模型
Outline
- 定時進行資料的ETL和雲端資料庫的同步
- 定時運作的學習系統
- 自動在雲端布署實驗系統
- 自製和管理R的套件
- 利用客製化的Dashboard來監控系統成效
- R 套件和CI(Continuous Integration)
- 利用CRAN套件進行系統狀態的通知
定時進行資料的ETL和雲端資料庫的同步
Extract, Transform, and Load
想要我的財寶嗎?想要的話可以全部給你
去爬吧!我把所有的資訊都放在那裡了。
基礎工程能力
請期待社群接下來的線上、實體課程
給一些資料源
impression201406012300.txt
製作一個R script處理檔案並不難
in_path <- readLines("impression2014060123.txt")
# 我爬, 我爬, 我爬爬爬
saveRDS(out, "out.Rdata")
資料源是資料庫?
R 有豐富資料庫相關的套件

但是資料一直在變化
需要把一次性的工作變成持續性
需要讓工作能夠自動化
定時啟動系統:
crontab,工作排程
jenkins 
利用時間建立不同的行為
R 有豐富的時間相關工具函數

事情不會永遠美好...
我們需要寫記錄(Log)
我們需要處理錯誤
R 也有許多寫log用的套件

除錯後,需要追回耽誤的工作
R 也有豐富的檔案系統相關工具

為了和雲端(AWS S3)同步
python 有 boto
command line 有 awscli
R 可以站在這些工具上
R 提供system來呼叫命令列程序
cmd <- sprintf("aws s3api put-object --bucket %s --key %s --body %s %s %s",
bucket, key, path, md5base64, class)
retval <- system(cmd, return = TRUE)
回傳結果的JSON
可以利用rjson來處理
library(rjson)
fromJSON(retval)
一次性的程序和自動化程序的距離:
利用如jenkins等定時啟動器透過命令列呼叫Rscript
需要依賴時間做出不同的行為
能夠檢查先前的結果是否有誤
利用如logging等套件進行記錄
R 的擴充性
大量的套件提供的功能
利用system和字串處理來擴充功能
定時運作的學習系統

已經有定時、自動化的R 程式
我們可以來談談更複雜的需求
機器學習的模型有很多參數
參數需要調整
我們應該不想看到:
.
|--- LR_Scripts
|--- logistic_regression_C_0.1.R
|--- logistic_regression_C_0.1_Neg_Sample.R
|--- logistic_regression_C_0.5.R
|--- logistic_regression_C_1.0.R...
R 的程序是可以吃參數的
[1] "/opt/local/Library/Frameworks/R.framework/Resources/bin/exec/R"
[2] "--slave"
[3] "--no-restore"
[4] "-e"
[5] "library(slidify);slidify('index.Rmd')"
[6] "--args"
更可以利用套件如optparse
增強命令列參數的功能
預設參數
必要參數與可忽略參數
參數的說明
library(optparse)
opt <- parse_args(OptionParser(option_list=list(
make_option("--C", default=1.0, help="The value of regularization parameter"),
make_option("--NegSample", default=FALSE, help="Whether sample the negative data")
)))
Usage: optparse.example.R [options]
Options:
--C=C
The value of regularization parameter
--NegSample=NEGSAMPLE
Whether sample the negative data
-h, --help
Show this help message and exit
部署機器學習的結果時
很可能需要和其他工具溝通
透過資料庫很方便
R 擁有豐富的資料庫相關套件

也可以透過Rcpp + Boost Serialization
和其他工具傳遞Binary
更複雜的自動化工作
可利用命令列參數來調整行為
可利用資料庫和其他工具溝通
自動在雲端布署實驗系統
模型的參數需要調整
調整參數需要實驗
如何有效率的進行大量實驗
攸關企業的競爭力
跑實驗需要臨時性的運算資源
現在有許多雲端解決方案
提供彈性的運算資源
R 和AWS 的整合則較為間接
透過預先設定好的AMI
以及上述的AWSCLI
和命令列參數的整合
可以自動開出任意數量的虛擬機器跑實驗
訣竅和上述介紹的方法雷同
只是應用上更為複雜
obj@env$spot_request <- ec2_request_spot_instances(
obj@price,
obj@count,
local({
j <- gen_instance_spec(obj@key.name, obj@instance_type, list(obj@key.name), obj@ami)
j$BlockDeviceMappings <- list(list(DeviceName = "/dev/sdf", Ebs = list(VolumeSize = 50L)))
j
})
)
loginfo(sprintf("spot request id: %s", paste(get_spot_request_id(obj@env$spot_request), collapse=",")))
obj@env$instance_ids <- wait_spot_request(get_spot_request_id(obj@env$spot_request))
loginfo(sprintf("instance id: %s", paste(obj@env$instance_ids, collapse=",")))
obj@env$instances <- wait_instance_running(obj@env$instance_ids)
太過複雜的功能
使用一個個Scripts來管理非常不方便
library(optparse)
library(logging)
source("/home/wush/ec2/ec2_request_spot_instances.R")
source("/home/wush/ec2/get_spot_request_id.R")
source("ssh_agent.R")
source("learning.R")
# ...
在雲端上部署實驗環境也不方便
source("learning.R")
Error: 無法開啟連結
自製和管理R的套件
散布R 應用到其他機器
建議使用套件(package)
解決所有相依性問題
library(RAWSCLI)
只要用到對的工具
目前自製R 套件非常的容易
把跑機器學習的Scripts包成套件
讓雲端上的AMI來安裝套件
把寫好的R Scripts部署到雲端上
利用.Rprofile可以指向預設的套件庫
options(repos=structure(c(
My_R_Repository="http://xxx.xxx.xxx.xxx",
CRAN="http://cran.csie.ntu.edu.tw/",
omegahat="http://www.omegahat.org/R"
)))
架設R 的Private Repository很容易
Web Server
tools::write_PACKAGES
## Not run:
write_PACKAGES("c:/myFolder/myRepository") # on Windows
write_PACKAGES("/pub/RWin/bin/windows/contrib/2.9",
type = "win.binary") # on Linux
## End(Not run)
利用Jenkins + git + R
自動部署至Private Repository
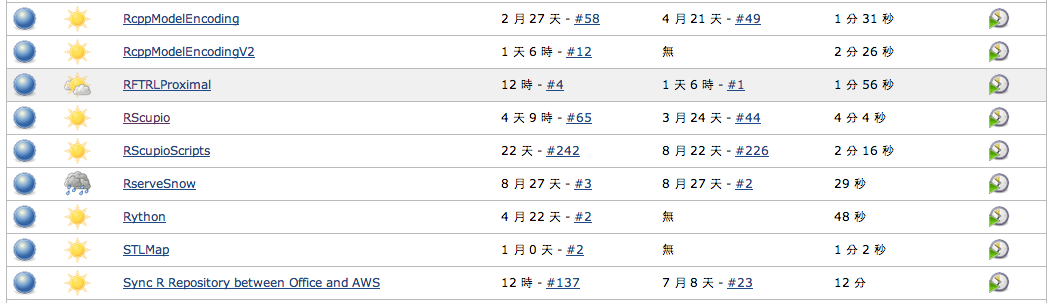
利用客製化的Dashboard來監控系統成效
2012年Rstudio Inc.發佈了Shiny套件
R 已經可以將分析結果變成網頁應用
利用R 定時分析資料
再利用Shiny Server
搭建Dashboard應用服務
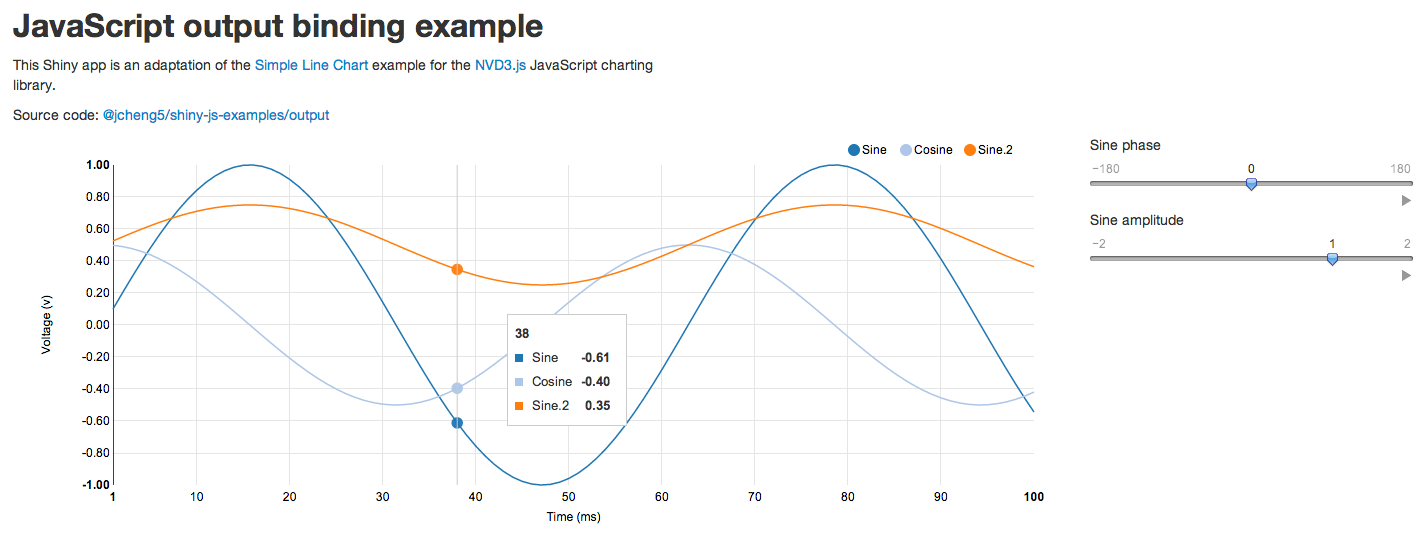
搭配R 強大的繪圖功能

Shiny 的使用上,社群也有許多學習資源
R 套件和CI(Continuous Integration)
R 的套件原始碼
可以利用git來管理
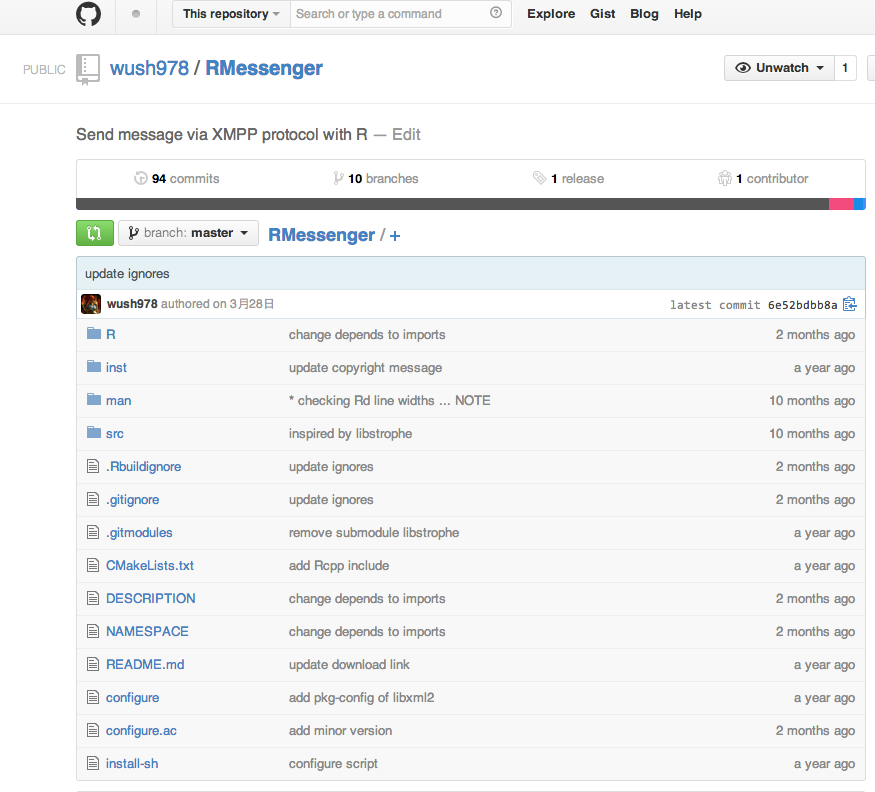
R 本身備有以下套件相關的功能:
打包
測試
部署
能和CI工具整合
R CMD check 就可以運作各種測試
RUnit, testthat, svUnit
協助寫單元測試
R + Web Service(如: Apache)
建立私有Repository
CI工具部署套件至私有Repository
再通知其他機器更新套件
Jenkins 已有支援R 的Plugin
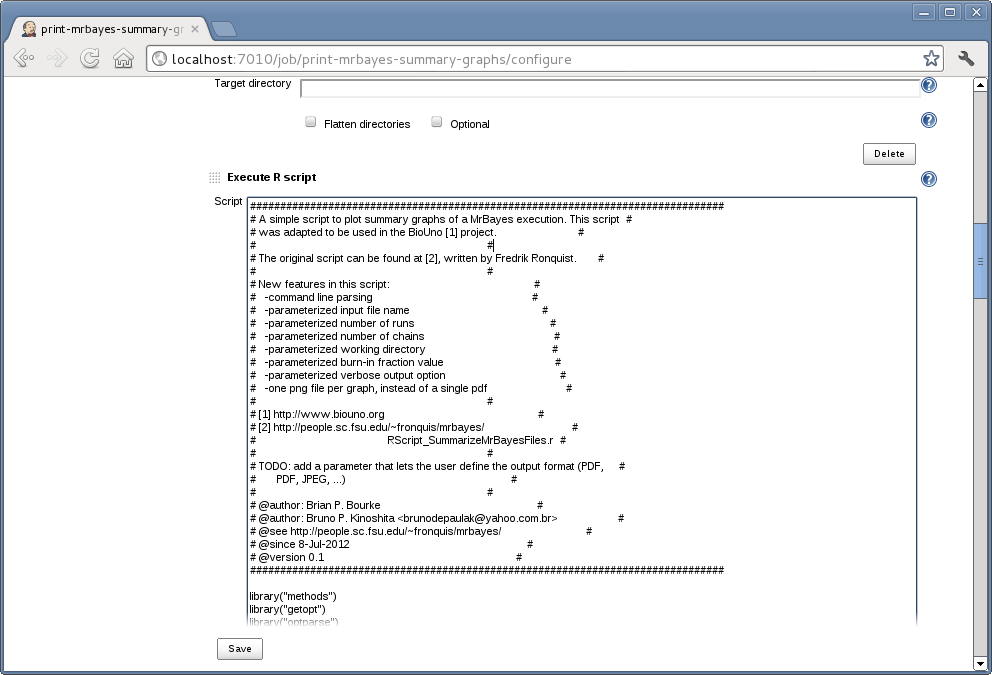
另一個CI的工具:
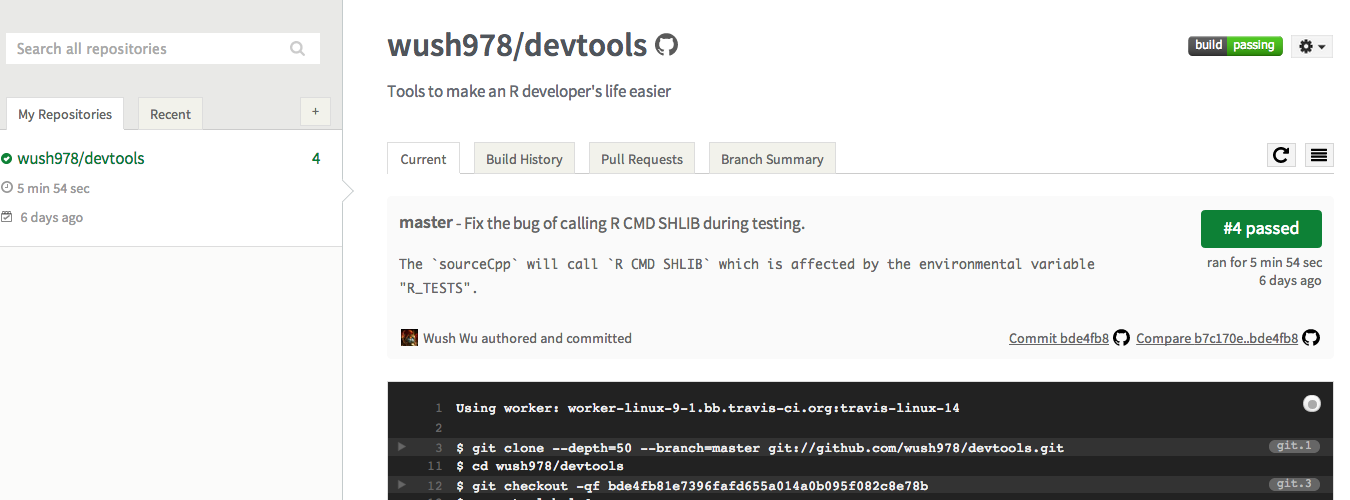
Work Flow
本地端開發完成,更新版本,git push到git repository
jenkins獲知git repository已更新,開始套件的測試
套件測試通過,利用R CMD部署套件到私有R Repository
連線到其他機器,自動更新到最新版本的套件
出現錯誤,需要退版
可以指定需要安裝的套件版本
base::numeric_version
利用CRAN套件進行系統狀態的通知
當出現嚴重錯誤時
若我們希望能及時收到通知
可以利用如RMessenger等套件
R 可以自定錯誤發生後的行為
options(error = function() {
library(RMessenger)
sendXMPPMessage("sender@gmail.com", "senderpass", "your@gmail.com",
geterrmessage())
})
感謝各位的聆聽
Q&A
已經有定時、自動化的R 程式
我們可以來談談更複雜的需求
機器學習的模型有很多參數
參數需要調整
我們應該不想看到:
.
|--- LR_Scripts
|--- logistic_regression_C_0.1.R
|--- logistic_regression_C_0.1_Neg_Sample.R
|--- logistic_regression_C_0.5.R
|--- logistic_regression_C_1.0.R...
R 的程序是可以吃參數的
[1] "/opt/local/Library/Frameworks/R.framework/Resources/bin/exec/R"
[2] "--slave"
[3] "--no-restore"
[4] "-e"
[5] "library(slidify);slidify('index.Rmd')"
[6] "--args"
更可以利用套件如optparse
增強命令列參數的功能
預設參數
必要參數與可忽略參數
參數的說明
library(optparse)
opt <- parse_args(OptionParser(option_list=list(
make_option("--C", default=1.0, help="The value of regularization parameter"),
make_option("--NegSample", default=FALSE, help="Whether sample the negative data")
)))
Usage: optparse.example.R [options]
Options:
--C=C
The value of regularization parameter
--NegSample=NEGSAMPLE
Whether sample the negative data
-h, --help
Show this help message and exit
部署機器學習的結果時
很可能需要和其他工具溝通
透過資料庫很方便
R 擁有豐富的資料庫相關套件
也可以透過Rcpp + Boost Serialization
和其他工具傳遞Binary
更複雜的自動化工作
可利用命令列參數來調整行為
可利用資料庫和其他工具溝通
自動在雲端布署實驗系統
模型的參數需要調整
調整參數需要實驗
如何有效率的進行大量實驗
攸關企業的競爭力
跑實驗需要臨時性的運算資源
現在有許多雲端解決方案
提供彈性的運算資源
R 和AWS 的整合則較為間接
透過預先設定好的AMI
以及上述的AWSCLI
和命令列參數的整合
可以自動開出任意數量的虛擬機器跑實驗
訣竅和上述介紹的方法雷同
只是應用上更為複雜
obj@env$spot_request <- ec2_request_spot_instances(
obj@price,
obj@count,
local({
j <- gen_instance_spec(obj@key.name, obj@instance_type, list(obj@key.name), obj@ami)
j$BlockDeviceMappings <- list(list(DeviceName = "/dev/sdf", Ebs = list(VolumeSize = 50L)))
j
})
)
loginfo(sprintf("spot request id: %s", paste(get_spot_request_id(obj@env$spot_request), collapse=",")))
obj@env$instance_ids <- wait_spot_request(get_spot_request_id(obj@env$spot_request))
loginfo(sprintf("instance id: %s", paste(obj@env$instance_ids, collapse=",")))
obj@env$instances <- wait_instance_running(obj@env$instance_ids)
太過複雜的功能
使用一個個Scripts來管理非常不方便
library(optparse)
library(logging)
source("/home/wush/ec2/ec2_request_spot_instances.R")
source("/home/wush/ec2/get_spot_request_id.R")
source("ssh_agent.R")
source("learning.R")
# ...
在雲端上部署實驗環境也不方便
source("learning.R")
Error: 無法開啟連結
自製和管理R的套件
散布R 應用到其他機器
建議使用套件(package)
解決所有相依性問題
library(RAWSCLI)
只要用到對的工具
目前自製R 套件非常的容易
把跑機器學習的Scripts包成套件
讓雲端上的AMI來安裝套件
把寫好的R Scripts部署到雲端上
利用.Rprofile可以指向預設的套件庫
options(repos=structure(c(
My_R_Repository="http://xxx.xxx.xxx.xxx",
CRAN="http://cran.csie.ntu.edu.tw/",
omegahat="http://www.omegahat.org/R"
)))
架設R 的Private Repository很容易
Web Server
tools::write_PACKAGES
## Not run:
write_PACKAGES("c:/myFolder/myRepository") # on Windows
write_PACKAGES("/pub/RWin/bin/windows/contrib/2.9",
type = "win.binary") # on Linux
## End(Not run)
利用Jenkins + git + R
自動部署至Private Repository
利用客製化的Dashboard來監控系統成效
2012年Rstudio Inc.發佈了Shiny套件
R 已經可以將分析結果變成網頁應用
利用R 定時分析資料
再利用Shiny Server
搭建Dashboard應用服務
搭配R 強大的繪圖功能
Shiny 的使用上,社群也有許多學習資源
R 套件和CI(Continuous Integration)
R 的套件原始碼
可以利用git來管理
R 本身備有以下套件相關的功能:
打包
測試
部署
能和CI工具整合
R CMD check 就可以運作各種測試
RUnit, testthat, svUnit
協助寫單元測試
R + Web Service(如: Apache)
建立私有Repository
CI工具部署套件至私有Repository
再通知其他機器更新套件
Jenkins 已有支援R 的Plugin
另一個CI的工具:
Work Flow
本地端開發完成,更新版本,git push到git repository
jenkins獲知git repository已更新,開始套件的測試
套件測試通過,利用R CMD部署套件到私有R Repository
連線到其他機器,自動更新到最新版本的套件
出現錯誤,需要退版
可以指定需要安裝的套件版本
base::numeric_version
利用CRAN套件進行系統狀態的通知
當出現嚴重錯誤時
若我們希望能及時收到通知
可以利用如RMessenger等套件
R 可以自定錯誤發生後的行為
options(error = function() {
library(RMessenger)
sendXMPPMessage("sender@gmail.com", "senderpass", "your@gmail.com",
geterrmessage())
})
感謝各位的聆聽
Q&A
模型的參數需要調整
調整參數需要實驗
如何有效率的進行大量實驗
攸關企業的競爭力
跑實驗需要臨時性的運算資源
現在有許多雲端解決方案
提供彈性的運算資源
R 和AWS 的整合則較為間接
透過預先設定好的AMI
以及上述的AWSCLI
和命令列參數的整合
可以自動開出任意數量的虛擬機器跑實驗
訣竅和上述介紹的方法雷同
只是應用上更為複雜
obj@env$spot_request <- ec2_request_spot_instances(
obj@price,
obj@count,
local({
j <- gen_instance_spec(obj@key.name, obj@instance_type, list(obj@key.name), obj@ami)
j$BlockDeviceMappings <- list(list(DeviceName = "/dev/sdf", Ebs = list(VolumeSize = 50L)))
j
})
)
loginfo(sprintf("spot request id: %s", paste(get_spot_request_id(obj@env$spot_request), collapse=",")))
obj@env$instance_ids <- wait_spot_request(get_spot_request_id(obj@env$spot_request))
loginfo(sprintf("instance id: %s", paste(obj@env$instance_ids, collapse=",")))
obj@env$instances <- wait_instance_running(obj@env$instance_ids)
太過複雜的功能
使用一個個Scripts來管理非常不方便
library(optparse)
library(logging)
source("/home/wush/ec2/ec2_request_spot_instances.R")
source("/home/wush/ec2/get_spot_request_id.R")
source("ssh_agent.R")
source("learning.R")
# ...
在雲端上部署實驗環境也不方便
source("learning.R")
Error: 無法開啟連結
自製和管理R的套件
散布R 應用到其他機器
建議使用套件(package)
解決所有相依性問題
library(RAWSCLI)
只要用到對的工具
目前自製R 套件非常的容易
把跑機器學習的Scripts包成套件
讓雲端上的AMI來安裝套件
把寫好的R Scripts部署到雲端上
利用.Rprofile可以指向預設的套件庫
options(repos=structure(c(
My_R_Repository="http://xxx.xxx.xxx.xxx",
CRAN="http://cran.csie.ntu.edu.tw/",
omegahat="http://www.omegahat.org/R"
)))
架設R 的Private Repository很容易
Web Server
tools::write_PACKAGES
## Not run:
write_PACKAGES("c:/myFolder/myRepository") # on Windows
write_PACKAGES("/pub/RWin/bin/windows/contrib/2.9",
type = "win.binary") # on Linux
## End(Not run)
利用Jenkins + git + R
自動部署至Private Repository
利用客製化的Dashboard來監控系統成效
2012年Rstudio Inc.發佈了Shiny套件
R 已經可以將分析結果變成網頁應用
利用R 定時分析資料
再利用Shiny Server
搭建Dashboard應用服務
搭配R 強大的繪圖功能
Shiny 的使用上,社群也有許多學習資源
R 套件和CI(Continuous Integration)
R 的套件原始碼
可以利用git來管理
R 本身備有以下套件相關的功能:
打包
測試
部署
能和CI工具整合
R CMD check 就可以運作各種測試
RUnit, testthat, svUnit
協助寫單元測試
R + Web Service(如: Apache)
建立私有Repository
CI工具部署套件至私有Repository
再通知其他機器更新套件
Jenkins 已有支援R 的Plugin
另一個CI的工具:
Work Flow
本地端開發完成,更新版本,git push到git repository
jenkins獲知git repository已更新,開始套件的測試
套件測試通過,利用R CMD部署套件到私有R Repository
連線到其他機器,自動更新到最新版本的套件
出現錯誤,需要退版
可以指定需要安裝的套件版本
base::numeric_version
利用CRAN套件進行系統狀態的通知
當出現嚴重錯誤時
若我們希望能及時收到通知
可以利用如RMessenger等套件
R 可以自定錯誤發生後的行為
options(error = function() {
library(RMessenger)
sendXMPPMessage("sender@gmail.com", "senderpass", "your@gmail.com",
geterrmessage())
})
感謝各位的聆聽
Q&A